

Мы делаем много мобильных приложений для бизнеса и видим, как постепенно меняется модель работы с данными. И хотя озера данных все еще относительно новый формат, в последнее время про них много говорят и спрашивают. Постарались разложить по полочкам, чем озера отличаются от хранилищ, как они работают и когда удобнее хранить данные из приложения в озере, а когда в хранилище.
Вводная о приложениях и данных
От приложения для бизнеса ждут, что оно будет собирать большие данные и переводить их в полезную аналитику. Оно и будет, но большие данные нужно где-то хранить.
Можно в хранилище — облачной среде для хранения обработанных, категоризированных данных. Перед размещением на хранение данные очищаются и классифицируется. Склад — самая подходящая аналогия. При поставке товары обрабатываются, стикеруются, переупаковываются на паллеты.

Можно в озере (Data Lake) — облачной среде для необработанных данных из операционных, транзакционных систем, внешних и внутренних источников. Здесь все как в настоящем озере: справа ручьи, снизу источник, сверху дождевая вода. Данные разные и хранятся в том же виде, в котором поступают.
Как работает озеро данных и чем отличается от хранилища
Данные загружаются в озера потоком или интервальной загрузкой. Так как в озера поступают очень разные файлы и потом их приходится как-то искать, можно помечать данные тегами и использовать для поиска специальные решения. Тот же ElasticSearch или его аналоги.
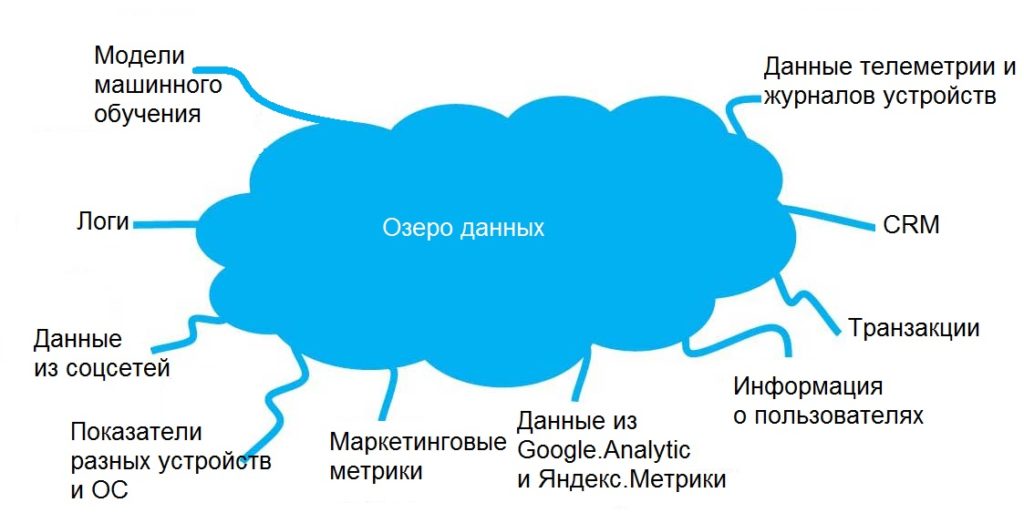
Архитектура
Главное, чем отличается озеро от хранилища — архитектурой. У озера она плоскостная, гибкая. Нет необходимости шаблонизировать поступающую информацию. Можно размещать ее как есть. Обрабатываться она будет потом, по мере необходимости.
В хранилищах данные сразу очищаются, обрабатываются и пользователи, которым они нужны, получают их в готовом виде.
Если оперировать терминологией баз данных, то озера похожи на нереляционные базы NoSQL, а хранилища на реляционные базы SQL.
Целевая аудитория
С озерами предпочитают работать специалисты по обработке данных. Здесь они могут извлекать разные сведения и преобразовывать их с помощью сборщиков. Например, AWS Glue Crawler, или трансформаторов, того же PySpark.
С хранилищами чаще работают бизнес-аналитики. Там хранятся структурированные, шаблонизированные данные. Их легко перемещать, объединять и интерпретировать даже без специальных программных инструментов.
Безопасность
У хранилищ чуть понадежней система безопасности. Прежде чем отправиться на хранение, данные обязательно проверяются. В озера же поступают огромные массивы необработанных, непроверенных данных из разных источников. Вот почему важно продумать систему контроля. Хотя бы базовую, с фиксацией действий в журнале и шифрованием.
Преимущества озера данных
Data Lake хороши для анализа информации из большого количества источников. А еще в тех случаях, когда сведения проблематично обрабатывать перед размещением.
Например, при интеграции приложения с интернетом вещей (данные телеметрии и журналов устройств) или с моделями машинного обучения. Удобно «сливать» в озера данные для анализа трафика, сигналов, заявок из социальных сетей. Удобно отслеживать работу приложения на устройствах сотен разных моделей и под разными ОС. И сложно найти что-то практичнее озера для поддержки объемных гетерогенных, мультирегиональных и микросервисных сред.
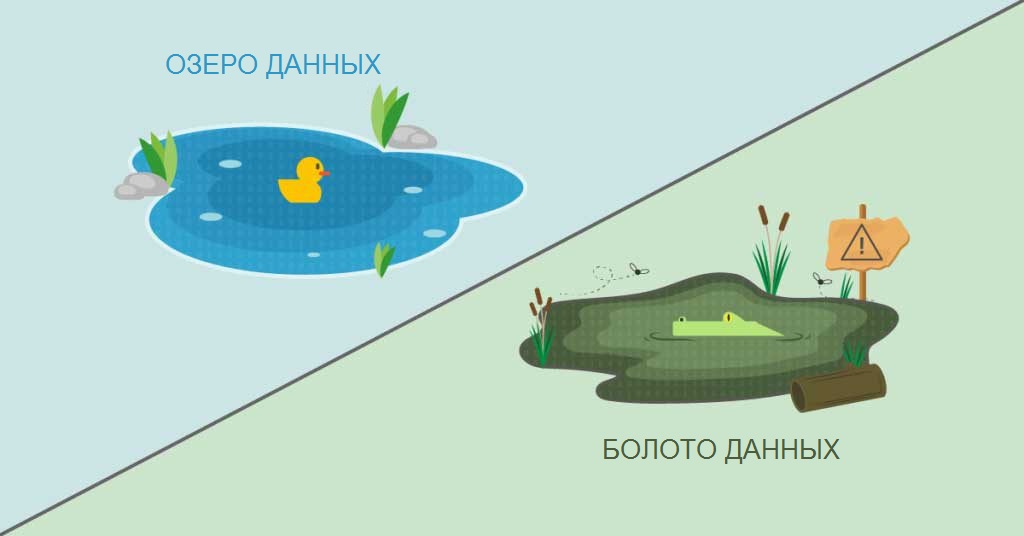
В простоте архитектуры озер кроется серьезная проблема. Нешаблонная структура легко превращается в болото данных, когда в облако стекаются некачественная, мусорная информация. Обойти эту проблему озера данных помогает простейшая система фильтрации:
- сделать аудит источников и отсечь заведомо некачественные,
- установить лимит параметров, не допуская до загрузки, допустим, слишком маленькие или слишком большое файлы,
- использовать метаданные при первичной регистрации.
Когда озера данных удобнее хранилищ?
Когда есть массив сырой необработанной информации. В том числе из источников, которые никак не пересекаются, а вы хотите иметь возможность обдумать, покрутить все это богатство так и эдак.
В качестве примера возьмем страховую компанию. У бухгалтерского отдела свои показатели и отчеты. У экономического — другие. Отдел урегулирования рассматривает страховые случаи и принимает решение о выплате возмещений.. Инвестиционный отдел работает с активами, покрывающими страховые выплаты, а также оценивает коммерческие риски, наблюдает за биржевыми индексами. Маркетологи отслеживают CAC, CR и AOV, тестируют гипотезы, собирают данные из Google.Analytic и Яндекс.Метрики.
Разная статистика, разные единицы измерения, разные задачи. Чтобы увидеть целостную картину, придется сначала собрать данные из всех репозиториев и баз, а потом переводить их в одну плоскость.
Если же аккумулировать все данные в озере — метрики маркетологов, показатели отдела продаж, бухгалтерскую отчетность, инвестиционные риски и пр. — можно брать все сведения в одном месте, структурировать, тасовать и отслеживать интересные закономерности. Например, что при ужесточении денежно-кредитной политики в стране стабильно растет спрос на ипотечную страховку. Или при перезаключении корпоративных договоров ДМС 90% застрахованных сотрудников покупают у этого же страховщика полисы ОСАГО и дополнительные страховые продукты. Если копнуть глубже, найдутся и другие ценные инсайты.
Инсайты и неочевидные открытия из разрозненных сведений— главное преимущество озер данных.
Data Lake на практике
Пожалуй, самый наглядный и интересный пример масштабного использования озер данных в российских реалиях можно подсмотреть у «Норникеля».
Предприятие состоит из десятков филиалов и технологических групп. У многих свои информационные и технологические системы. Плюс разное оборудование, которое транслирует в них данные. Раньше все это приходилось перерабатывать и унифицировать, чтобы использовать в одной среде и задействовать возможности машинного обучения. Весной 2021 года «Норникель» запустил корпоративное Data Lake. Теперь в озеро поступают данные не только из производственного блока, но и кадровые сведения. Это позволило связать показатели производства с HR-метриками. Как следствие, компания получила возможность снизить процент нарушения технологий, расширить горизонты оптимизации технологических процессов, ускорить принятие решений.
Другой пример, но уже из-за рубежа — Amazon. Несколько лет назад финансовые транзакции компании хранились в 25 разных базах. У разработчиков было отдельное хранилище, аналитики пользовались своим репозиторием. Все эти базы были устроены по-разному. Чтобы найти компоненты в базе смежников, трансформировать их в нужный формат и посмотреть на корреляцию, уходила масса времени. Сейчас Amazon собирает все данные в озере. Аналитики, разработчики, маркетологи и другие специалисты компании извлекают оттуда нужные сведения, используя каждый свои инструменты.

Возможно, со временем озера станут глобальным трендом big data. Не для всех и не всегда, но как одна из ступеней для более глубокой проработки сложных алгоритмов и аналитики — точно. В любом случае, если решите воспользоваться, вспомните, что данные — в хранилище или в озере — ценны только в том случае, если вы можете переложить их в практическую плоскость.